| Day | Topic |
|---|---|
| Wed, Jan 17 | Vectors and matrices |
| Fri, Jan 19 | Markov chains |
Today we reviewed vectors and matrices. Recall that a vector is all three of the following things:
We denote the set of all real number vectors with entries by . Recall that the length of a vector (also known as the norm) is:
We also talked about how to multiply vectors by constants (scalar multiplication) and how to calculate the dot product (see this Kahn academy video for example). We stated (without proof) the fact that for any two vectors , where is the angle between the vectors and . We finished our review of vectors by saying that two vectors are orthogonal when . Then the orthogonal complement of a single vector is the set If is a nonzero vector, then is an -dimensional hyperspace inside of .
After reviewing vectors we reviewed matrices and how to multiply matrices. We did the following example in class:
We finished by talking briefly about this problem from Introduction to Probability by Grinstead & Snell:
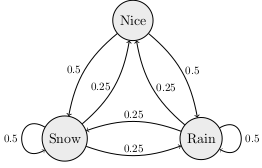
Today we looked in more detail at the Land of Oz Markov chain from last time. We started by defining the following terminology.
A Markov chain is a model with stages where the next state is randomly determined based only on the current state. A Markov with states can be described by a transition matrix which has entries equal to the probability that the next state will be if the current state is . In the Land of Oz example, if the states Nice, Rain, Snow correspond to the row/column numbers 0, 1, 2, respectively, then the transition matrix is
A probability vector is a vector with nonnegative entries that add up to 1. You can use probability vectors to model your knowledge about the current state in a Markov chain. For example, if it were raining today in the Land of Oz, then you could use the probability vector to indicated that we are 100% sure that we are in the middle state (raining). If you multiply , then you get the probability row vector representing the probabilities for the states the next day. Here is how to use matrices in the Python using the numpy library.
import numpy as np
Q = np.matrix("0 0.5 0.5; 0.25 0.5 0.25; 0.25 0.25 0.5")
v = np.matrix("0 1 0")
print(v * Q)Suppose that today is a nice day. What is the probability vector that describes how the weather might be the day after tomorrow?
What will the weather be like after 1 week if today is nice? What about if today is rainy or snowy? How much difference does the weather today make after 1 week? You can answer this last problem by computing .
We finished with this additional example which is problem 5.7.12 in Introduction to Finite Mathematics by Kemeny, Snell, Thompson.
| Day | Topic |
|---|---|
| Mon, Jan 22 | Examples of Markov chains |
| Wed, Jan 24 | Stationary distributions |
| Fri, Jan 26 | Random text generation |
Today we did the following workshop about Markov chains.
Today we talked about some of the features we’ve seen in Markov chains. Recall that you can think of a Markov chain as a weighted directed graph where the total weight of all the edges leaving a vertex must add up to 1 (the weights correspond to probabilities).
In all of the examples we’ve considered so far, we have looked for the final long run probabilities for the states after many transitions.
Definition. A probability vector is a stationary distribution for a Markov chain with transition matrix if
In all of the examples we’ve looked at, exists and is a stationary distribution for any initial probability vector . But this doesn’t always happen for Markov chains.
To better understand the long-run behavior of Markov chains, we need to review strongly connected components of a directed graph (digraph for short).
Definition. A digraph is strongly connected if you can find a path from any start vertex to any other end vertex . A strongly connected component of a graph is a set of vertices such that (i) you can travel from any one vertex in the set to any other, and (ii) you cannot returns to the set if you leave it. Strongly connected components are also known as classes and they partition the vertices of a directed graph. A class is final if there are no edges that leave the class.

In the digraph above, there is one final class and two other non-final classes.
Theorem (Perron-Frobenius). A Markov chain always has a stationary distribution. The stationary distribution is unique if and only if the Markov chain has only one final class.
We did not prove this theorem, but we did apply it to the following question.
Which of the Markov chains that we’ve considered (the Land of Oz, the Tardy Professor, the Gambler’s Ruin problem, and the Coupon Collector’s problem) has a unique stationary distribution? For the one(s) that don’t have a unique stationary distribution, describe two different stationary distributions.
Does the Markov chain that doesn’t converge from Q1 today have a unique stationary distribution? How can you tell? Can you find it?
Another important is question is to have criteria for when converges.
Definition. A Markov chain with transition matrix is regular if there is a power such that has all positive entries.
Theorem. A regular Markov chain with transition matrix always has a unique stationary distribution and for any initial probability vector ,
We finished class by talking about how the Google PageRank algorithm uses the stationary distribution of a simple regular Markov chain to rank websites. The algorithm starts by imagining a random web surfer who clicks on links completely randomly to visit new website. You can imagine the internet as a giant directed graph and this websurfer can be modeled with an state Markov chain where is the number of websites on the internet. Unfortunately the -by- transition matrix might not be regular, so the PageRank algorithm creates a new regular Markov chain by using the following algorithm:
The 85/15 percent split was chosen because the resulting regular Markov chain converges relatively quickly (it still takes days for the computation to update), but it still settles on a stationary distribution where more popular websites are visited more than less popular websites.
Today we wrote a program to randomly generate text based on a source text using a Markov chain.
Here are some example source texts you can use. You can also search online for other good examples if you want. When you are finished, you should have a program that can generate random nonsense like this:
In the beginning when God created the great sea monsters and every winged bird of every kind on earth that bear fruit with the seed in it." And it was good. And there was morning, the second day. And God saw that it was good. Then God said, "Let there be lights in the dome and separated the waters that were gathered together he called Night. And there was evening and there was morning, the fourth day. And God saw that the light Day, and the waters bring forth living creatures of every kind, and everything that has the breath of life, I have given you every plant yielding seed of every kind, and trees of every kind bearing fruit with the seed in it.
| Day | Topic |
|---|---|
| Mon, Jan 29 | Least squares regression |
| Wed, Jan 31 | Least squares regression - con’d |
| Fri, Feb 2 | Logistic regression |
Today we started talking about linear regression. We started with the simplest case where you want to predict a response variable () using a single explanatory variable (). Based on the observed and values, you want to find the best fit trend-line. We judge how good a trend-line fits the data by calculating the sum of squared deviations between the predicted -values (denoted ) and the actual -values () at each .
We’ll see later that minimizing the sum of squared error has some nice properties. We looked at the following example.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("http://people.hsc.edu/faculty-staff/blins/classes/spring18/math222/data/bac.csv")
print(df)
x = np.array(df.Beers)
y = np.array(df.BAC)
plt.xlabel("Beers")
plt.ylabel("BAC")
plt.plot(x,y,"o")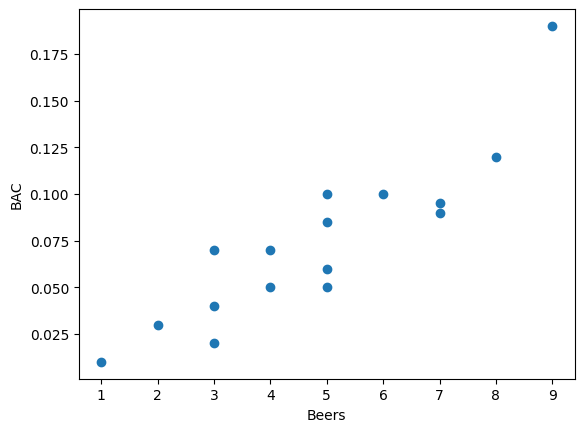
The least squares regression line will have a formula where is the -intercept and is the slope. You can find these two numbers by using the normal equation
where is a column vector with the intercept and slope that we want to find, is the column vector with the -values from the data, and is an -by-2 matrix will all 1’s in its first column and the -values from the data in its second column. The notation means that transpose of the matrix , which is the matrix you get if you switch all columns of to rows: One way to solve the normal equations is to multiply both sides by the inverse of the matrix :
The inverse of a matrix is denoted . You can only find the inverse of square matrices (same number of rows & columns). Even then, not every square matrix has an inverse, but this formula almost always works for least squares regression. I only gave a vague explanation in class of why the normal equations work. But we did use Python to compute the normal equations for the example above:
X = np.matrix([[1.0 for i in range(len(x))],list(x)]).T
beta = (X.T*X).I*X.T * np.matrix(y).T
print(beta) # [[-0.0127006 ], [ 0.01796376]]Notice that if A is a numpy matrix, then A.T is its transpose, and A.I is its inverse (if one exists). The entries of are the intercept followed by the slope, so the least squares regression line for predicting blood alcohol content from the number of beers someone drinks is:
In addition, we can tell from the slope that each extra beer someone drinks tends to increase their BAC by 0.018 points.
Today we continued looking at least squares regression. We covered these additional facts about the least squares regression line when there is only one explanatory variable ().
Here and denote the average and -values respectively, and are the standard deviations of the and -values, and is the correlation coefficient. We defined these quantities using the norm (length) and dot products.
We used a spreadsheet to investigate these examples.
In the USA, there has been a striking decline in the number of people killed by lightning every year. The trend is strong, but it isn’t really a linear trend. So we used the normal equations to find a best fit quadratic polynomial Here is how to do this with numpy.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("http://people.hsc.edu/faculty-staff/blins/StatsExamples/Lightning.xlsx")
x = np.array(df.year)
y = np.array(df.deaths)
# You can use a list comprehension to enter the matrix X.
X = np.matrix([[xi**k for k in range(3)] for xi in list(x)])
beta = (X.T*X).I*X.T * np.matrix(y).T
print(beta) # [[5.61778330e+04], [-5.42074197e+01], [ 1.30717749e-02]]
years = np.array(range(1960,2021))
plt.xlabel("Year")
plt.ylabel("Fatalities")
plt.plot(x,y,"o") + plt.plot(years,56177.8 - 54.207*years + 0.01307*years**2,linestyle="-")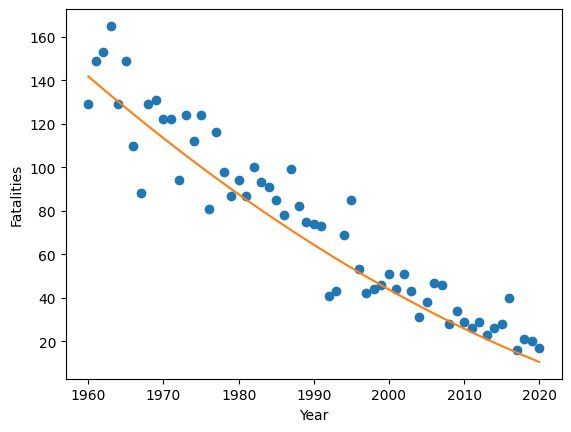
Today we did this workshop.
Here is the Python code to download the two datasets:
import numpy as np
import pandas as pd
df = pd.read_excel("https://people.hsc.edu/faculty-staff/blins/classes/spring23/math121/halfmarathon.xlsx")
genders = list(df.Gender)
ages = list(df.Age)
minutes = list(df.Minutes)
df2 = pd.read_excel("http://people.hsc.edu/faculty-staff/blins/StatsExamples/Lightning.xlsx")
years = np.array(df2.year)
deaths = np.array(df2.deaths)
logDeaths = np.log(deaths) # notice that functions work elementwise on np.arrays.| Day | Topic |
|---|---|
| Mon, Feb 5 | Linear classifiers |
| Wed, Feb 7 | Loss functions & gradient descent |
| Fri, Feb 9 | Stochastic gradient descent |
Last time we saw came up with a model to predict a runner’s race time based on their age and gender. Our model had the form where is the predicted race time in minutes, is the runner’s age, and is an indicator variable which is 0 for men and 1 for women. An indicator variable is a numerical variable that is 1 if a Boolean condition is true and 0 otherwise. We can re-write our model using a dot product as: In this formula, the vector is called the weight vector and is called the feature vector. Each runner has a different feature vector, but you use the same weight vector for every runner to make a prediction about their race time.
If we use age and race time to predict gender using least squares, then we get this formula: We could use the number as a dividing line to separate runners who we would predict are female vs. runners we would predict are male. This is a simple example of a linear classifier. A linear classifier is a rule that uses a weight vector and a feature vector and a threshold to decide how to classify data. You make a prediction based on whether the dot product is greater than or less than the decision threshold . If we treated men as instead of , then we could use the threshold , which is a more common choice for linear classification.
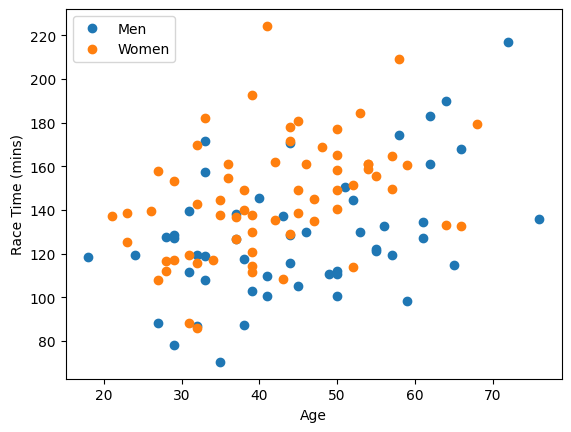
We were able to draw a picture of the line the separates individuals we would predict are women from individuals we would predict are men in the scatter plot for runners. If we had more than two variables, then we wouldn’t be able to draw a picture. And instead of a dividing line, we would get a dividing hyperplane to separate our predictions. But we could still use the same idea.
Using least squares regression to find our weight vector probably isn’t the best choice since the goal of least squared error isn’t really what we want. What we really want is the smallest zero-one error. Zero-one error is the error you get if you add a one for every prediction that is incorrect and a zero for every correct prediction. Both least squares error and zero-one error are examples of loss functions which measure how accurate our predictions are.
We finished by outlining where we are going in the next few classes. We are going to look at how to minimize different loss functions over the space of all possible weight vectors (called the weight space). We talked about how precise formulas for the optimal weight vector don’t always exist, but we can use a general technique called gradient descent that works for many different loss functions.
We talked about gradient descent today. For a multivariable function , the gradient of at a point is the vector We calculated the gradient for these examples. Here is a video that explains partial derivatives.
The important thing to understand about is that it always points in the direction of steepest increase. This idea leads inspires gradient descent which is a simple algorithm to find the minimum of a multivariable function.
Gradient Descent Algorithm. To find the minimum of ,
Here is the code I wrote in class to implement this algorithm for example 2 above.
import numpy as np
# Step 1 initialize initial guess x and step size eta.
x = np.array([0,0])
eta = 0.1
for i in range(20):
# step 2 calculate gradient
gradient = np.array([4*x[0]**3+2*x[0]-2, 4*x[1]**3+1])
# step 3 use the gradient to update x
x = x - eta*gradient
print(x, gradient)You have to be careful when you pick the step size (eta). If it is too big, the algorithm will not converge. If it is too small, the algorithm will be very slow.
Try the code above with different values of . What happens if ? What about ?
What will happen if you use gradient descent on a function like this one which has more than one local min?
Find the gradient of the following sum of squared error loss function. Then use gradient descent to find the vector with the minimum loss.
Today we did this workshop in class:
As part of the workshop, we introduced the stochastic gradient descent algorithm which tends to be an effective way to get gradient descent to converge more quickly.
Stochastic Gradient Descent Algorithm. Let be a sum of simpler loss functions . To minimize the total loss ,
| Day | Topic |
|---|---|
| Mon, Feb 12 | Hinge Loss |
| Wed, Feb 14 | Logistic regression |
| Fri, Feb 16 | Nonlinear classification |
In the workshop last time, we had to calculate the gradient of a function of the form . This is a composition of the one variable function with the dot product . In general, we have the following nice lemma which is one special case of the chain rule.
Lemma. If is differentiable, and , then
Today we looked at linear classification and talked about some of the different loss functions that we could use. We used the lemma above to help find the gradients for gradient descent. First we introduced the following terminology.
Suppose that we want to train a linear classifier. For each individual observed we have a feature vector and a category which is either or . Our goal is to find the best weight vector so for any observed feature vector , the sign of does the best possible job of predicting the corresponding value of . We call the number the score of the prediction. If we multiply the score times the correct value of , then we will get a positive number if the prediction is correct and a negative number if our prediction is wrong. We call this number the margin and
The hinge loss function is a function of the margin that is
Show that for each pair and , the gradient of the hinge loss is
Express the zero-one loss function as a function of the margin. Why won’t gradient descent work with zero-one loss?
We also looked at the absolute error loss function: and we calculated the gradient of that when is and .
With both hinge loss and absolute error loss, the gradient vectors don’t get small when we get close to the minimum, so we have to adjust the gradient descent algorithm slightly to use a step size that gets smaller after each step.
Gradient Descent Algorithm (with Variable Step Size). To find the minimum of ,
Today we talked about logistic regression which is one of the most common ways to find a linear classifier. In a logistic regression model the score is interpreted as the log-odds of a success.
Recall that the probability of any event is a number between 0 and 1. Sometimes in probability we talk about the odds of an event happening instead of the probability. The odds of an event is given by the formula For example, if an event has probability , then the odds are (we usually say 2 to 1 odds). You can also easily convert from odds back to probability by computing Unlike probabilities, odds can be bigger than 1. In logistic regression, we are looking for a model of the form For example, we came up with a very simple logistic regression model to predict whether someone is male or female based on their height: where height is measured in inches. We based this model on guessing the odds that someone is male or female at a couple different heights, and then guessing a simple linear trend for the log-odd.
Find the log-odds, the odds, and the probability that this model would give for someone who is 67 inches tall to be male.
If we randomly selected 3 people, with heights 64, 69, and 72 inches respectively, what is the probability (according to the model) that the 64 inch tall person is female and the other two are male? We call this number the likelihood of that event.
We guessed the slope and y-intercept in our model. Those probably aren’t the best possible coefficients. In logistic regression, we want the model that results in the highest likelihood of the actual data happening. We showed in class that the best coefficients happen when we minimize the logistic loss function which is the same as the negative logarithm of the likelihood function.
where is the probability of a “success” predicted by the model. We also noted that the gradient of the terms in the logistic loss function are So you can use (stochastic) gradient descent to find the best coefficients in a logistic regression model.
We looked at this example:
Today we talked about using linear classifiers to do nonlinear classification. The idea is that you can classify points based on a feature extractor function instead of on the raw values of . We used the example of finding the best circle to separate points inside from points outside. You can do this by using the feature extractor function and then finding the best parameters for the linear classifier Even though the classifier is a nonlinear function of the data it is still a linear function of the parameters , so you can still use the same gradient descent techniques we’ve already discussed.
We also talked about the dangers of complex models with lots of parameters and complicated feature extractors. These models tend to overfit the data, which means they predict the test data very well, but then fail on real world data.
We finished by starting this workshop.
| Day | Topic |
|---|---|
| Mon, Feb 19 | Review |
| Wed, Feb 21 | Midterm 1 |
| Fri, Feb 23 | Regularization |
Went over what you should know going in to the midterm on Wednesday. Make sure you know all of the terms in bold and how to do any of the indicated calculations by hand.
Today we looked at data from a large set of e-mails to determine which features indicate that the e-mail might be spam. We also implemented a technique called regularization where our goal is not just to minimize a loss function, but to minimize where the second term is a complexity function that gets larger as the weight vector gets more complicated. A simple, but commonly used, complexity function is the 1-norm (AKA -norm) of the weight vector In class we used gradient descent to minimize where is a loss function and is a regularization constant which is another hyperparameter we can adjust to tune our model. Larger values of tend to penalize large coefficients in the weight vector and also frequently lead to many less important variables getting a coefficient of zero. So regularization helps use find simpler models that are less likely to overfit the data.
We did the following two examples in class:
Example: Linear classifier for spam emails
| Day | Topic |
|---|---|
| Mon, Feb 26 | Neural networks |
| Wed, Feb 28 | Backpropagation |
| Fri, Mar 1 | Backpropagation - con’d |
Today we introduced neural networks. These are often depicted using graphs like this.

The image above shows a very simple neural network with just one hidden layer. It reads an input vector with three entries, and then find values for 4 nodes in the hidden layer, which are then used to find the values of the 2 nodes in the output layer.
The simplest types of neural networks are feed forward networks which are used to convert input vectors to output vectors using weights that are determined by training. More complicated neural networks (recurrent neural networks) can recycle their outputs back to input. We won’t worry about those for now.
All neural networks used in machine learning focus on a very simple type of function to go from one layer to the next. Each step from layer to layer is a function which combines an affine linear transformation where is a matrix and is a vector with a nonlinear activation function :
Common choices for the activation function are
Note: In class I wrote the formula for instead of when I defined the hyperbolic tangent on the board, which was a mistake. I also said that the hyperbolic tangent function is a sigmoid function, which is true, but there are other sigmoid functions. The one I’ve added above is the one many textbooks refer to as “the” sigmoid function.
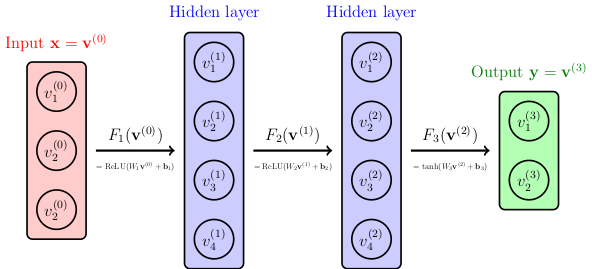
Notice that row of the matrix is a weight vector corresponding to all of the arrows that enter node in the -th layer of the neural network. The vector is called a bias vector and it contains the constant terms in the computation.
It is important to have a nonlinear activation function as part of each step between layers, otherwise we would just be composing (affine) linear maps, which would just result in a single (affine) linear map at the end.
We can still use (stochastic) gradient descent, but there are some caveats.
A neural network tends to have many more parameters than a simple linear classifier. Each entry of the matrices and the vectors is a parameter that needs to be considered as we minimize the loss function.
Because the loss functions tend to be very complicated, they might have more than one local minimum. A single run of gradient descent might get stuck in the wrong local minimum.
It’s very hard to know which settings (steps size, etc.) to choose to get gradient descent to work well.
Once we got these definitions out of the way, we took a look at this really cool website to get a feeling for how neural networks work and what they can do.
We played with creating some simple neural networks for different classification problems, and saw that more complicated problems required multiple layers. We also talked briefly about epochs, but we’ll talk about that in more detail later.
Today we introduced backpropagation which is an algorithm for finding the gradients of functions efficiently. It is one of the main ideas that makes working with neural networks feasible.
We started by describing how any formula built from simple building blocks like addition, multiplication, max, powers, etc. can be re-written using a computation graph.
Definition. A computation graph is a directed acyclic graph whose root node represents the final mathematical expression and every other node represents intermediate subexpressions.
We can label each node in a computation graph with the subexpression in the computation and possibly a variable name to represent that subexpression. A directed edge from a node to a node can be labeled with the partial derivative . Once we have a computation graph, the backpropagation algorithm works as follows.
Forward pass: Starting from the values of the nodes in the graph with node inbound edges, compute each subexpression in the graph.
Backward pass: Once you finish computing the final expression (the root), work backwards from the root to find the partial derivatives for every subexpression in the graph.
We did these examples in class:
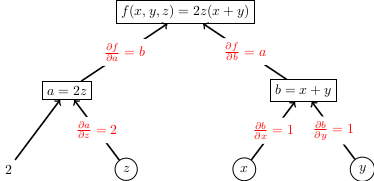
There is more than one way to create a computation graph for an expression, but you want to break the computation into many steps small so that it is easier to find the partial derivatives for each edge.
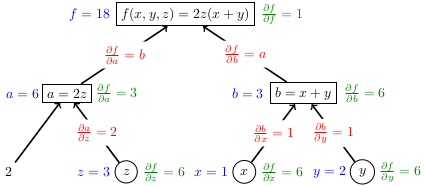
Therefore the gradient is .
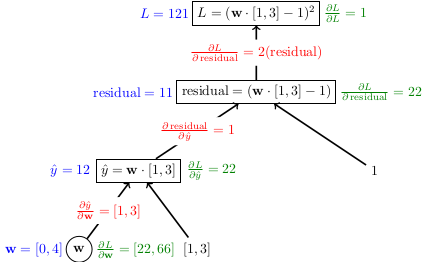
The gradient is .
One of the things we talked about in the last example is that is another notation for the gradient . They both represent the same thing.
If you want more examples (along with more explanation of the process) these slides from the Stanford CS221 course are worth looking over:
Today we did this workshop in class.
| Day | Topic |
|---|---|
| Mon, Mar 4 | Tensorflow introduction |
| Wed, Mar 6 | Classifying traffic signs |
| Fri, Mar 8 | Image convolution |
Today we introduced Tensorflow to create a neural network that can identify handwritten digits. The example we created in class is based on this TensorFlow 2 quickstart for beginners.
We started by downloading an example dataset (the MNIST dataset) that is included with TensorFlow. Then we trained a simple neural network with one hidden layer to classify numbers. We played around with it and found that it works pretty well on the training and test data, but doesn’t always work well on other handwritten examples.
In order to explain the model, we also introduced the softmax function. The code for two neural networks we trained is here:
Today I gave everyone time in class to create their own neural network to classify images of German street signs into one of three categories:
The images are stored as 32-by-32 numpy arrays of integers between 0 (black) and 255 (white). You can download the images using the following commands in Python:
import pickle
import urllib.request
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
images, labels = pickle.load(urllib.request.urlopen("https://bclins.github.io/spring24/cs480/trafficSigns.pkl"))
categories = ["stop sign","turn sign","speed limit sign"]
train_images, test_images, train_labels, test_labels = train_test_split(images,labels)Here pickle is a library that lets you store Python data in a file that other people can access. The URLlib lets you get the pickle data from my website. The last function train_test_split() from the Scikit-learn library lets us randomly separate some of the data to use for training and some to keep for testing our neural network after it is trained.
To see what the images look like, use a command like this:
i=0
print(images[i])
plt.imshow(images[i])
plt.gray()
plt.show()
Notice that this is a (German) speed limit sign, and has label labels[i] equal to 2, which is the correct label for a speed limit sign.
Here are a couple of issues that will come up as you do this.
You need to divide each image array by 255 (just like what we did on Monday) so that each entry is between 0 and 1. But because the data is a list of numpy arrays, you can’t just divide the whole list by 255 (unlike on Monday where the data was a single giant numpy array). So you’ll have to convert the variables train_images and test_images to numpy arrays:
import numpy as np
train_images = np.array(train_images)
test_images = np.array(test_images)Then it will be easy to scale everything by dividing by 255.
When you get to the command to train the TensorFlow model, it expects both the image data and the labels data to be numpy arrays not regular python lists. So you’ll have to convert train_labels and test_labels as well.
When you define the model, make sure to use the correct image size (32-by-32) for the inputs (not the 28-by-28 image size from Monday). Also, since we are only classifying three categories of signs, your final output layer only needs 3 nodes.
There are only 840 images in the data set, so each epoch should run pretty fast. You might want to do more than 5 epochs, but don’t do too many. Once the accuracy levels off, there is no point in running more epochs. Too many epochs increases the risk of overfitting the data.
In class, a lot of people got neural networks that were 100% accurate. That raises the following question:
Today we talked briefly about the idea of a convolutional neural network and image convolution without going into too many details. The idea is to add convolution layers to the model before the regular neural network layers.
Here is a nice video explanation of how image convolution works with a kernel matrix.
Here is the wikipedia entry about image convolution kernels with several examples.
After talking briefly about image convolution, we did this workshop in class:
| Day | Topic |
|---|---|
| Mon, Mar 18 | Unsupervised learning: k-means |
| Wed, Mar 20 | k-means clustering - con’d |
| Fri, Mar 22 |
Today we introduced the -means clustering algorithm which is a popular form of unsupervised learning. Unlike linear classifiers, regression, and neural networks which all need training data to learn from, unsupervised learning algorithms do not require any training information.
The goal of the -means clustering algorithm is to take a large collection of vectors and partition them into different sets (called clusters) so that the sum of the squared distances from each vector to the average of its cluster is minimized. We can summarize this goal by saying that we want to minimize the following objective function:
where is the average of the vectors in the cluster (sometimes called the centroid). Notice that the objective function is a function of the clusters , not the vectors. If we choose good clusters, then points in the clusters will be close together and the objective function will be small. If we choose bad clusters, then the points in a cluster will be spread out far from their average. Because clusters are discrete rather than continuous variables, we can’t use gradient descent to find the minimum, so we need an alternative. The -mean algorithm is a way to find clusters that minimize the objective function. It is not guaranteed to find the absolute minimum, but it tends to work well in practice.
Given a list of vectors , and an initial list of representative vectors repeat the following steps several times:
Update the partitition. Loop through the vectors . For each find the that is closest to and put into cluster .
Update the averages. Replace each with the average of cluster .
There are a couple of edge cases and other issues in the algorithm to consider.
To pick the initial representative vectors , one simple option is to just pick a random sample of size from the vectors . Other more complicated methods are available, but this simple option often works well.
If at any step a cluster is empty, then you can remove that cluster and its corresponding in the next round of the algorithm. It is okay to end up with fewer than clusters at the end.
If you get a tie when you calculate the minimum distances from to different , just use the lower as a tie breaker.
If there is a step in the algorithm where the cluster assignments don’t change, then you are done because from that point on you will always get the same clusters and averages .
The -means algorithm might only converge to a local minimum, so you might want to try different randomly chosen starting vectors to run the algorithm multiple times and get closer to the absolute minimum.
How do you know how many clusters to look for? The answer is that people usually try several different and look to see what works best.
We finished by looking at some examples of -means clustering.
We used it to group points in the 2-dimensional plane into clusters.
We also used it to cluster images of handwritten numerals.
Today we did a workshop in class to program the k-means algorithm and apply it to some data.
We looked at the following example data sets.
# Example 1
A=np.array([[3.39298264,1.94834851],[1.41747742,-1.06609251],[3.01888289,0.46840267],[2.59476459,1.13654766],[3.17962937,1.53188254],[4.82441491,1.1639604],[2.28793317,1.42545649],[3.92271615,-0.43760635],[1.3398049,0.69655122],[2.08559661,1.54877526],[0.62474841,1.83644512],[3.30539001,1.58518931],[2.60604184,1.54313128],[3.79532225,1.93029646],[3.18970132,1.37181024],[3.05993575,0.65569489],[2.72167775,1.14615515],[3.1319596,1.44343859],[2.04141107,1.16246335],[1.50404055,-0.72858893],[3.71654022,1.01262813],[2.15896926,-0.38455158],[3.68823967,0.83976529],[3.74768895,2.51485743],[2.60539076,1.59746209],[2.7209025,1.15981584],[2.74492997,0.49898255],[2.05625716,1.35438043],[3.35753586,0.72353369],[3.83737683,1.49555398],[4.16856373,-0.0796789],[2.72119861,0.48606978],[1.11115148,1.78233831],[2.28710689,0.52219863],[4.43789009,0.77498025],[2.63243216,0.20844207],[2.45771129,0.63496389],[4.58781488,0.84390828],[4.49266737,1.51652135],[2.19225968,-0.20082593],[-3.33108966,1.84044684],[-2.87952061,0.26483827],[-1.91099489,1.69754136],[-0.38340388,-0.77760197],[-3.27463826,2.28404138],[-2.82674904,1.10755789],[-3.58454208,2.46692198],[-2.7890395,3.35552427],[-2.13916854,2.91111573],[-1.75712374,2.91114338],[-0.19020027,3.05790698],[-1.03813622,1.68133303],[-2.45250168,2.00668745],[-3.32914595,2.98236229],[-2.7359661,0.74214967],[-2.14185246,1.5616797],[-1.14146589,2.77219574],[-1.17915129,2.97068053],[-3.91823034,2.36180472],[-2.77497322,2.75405217],[-1.74017177,-0.0112908],[-2.54457885,-0.08030844],[-2.24386365,1.68118681],[-2.13929886,1.80696979],[-3.38453642,1.91595502],[-2.74969769,2.98272972],[-2.02762516,2.28374355],[-1.57081931,0.95091447],[-2.25055478,2.97364212],[-2.05333346,2.21319462],[-0.30966156,1.68360366],[-2.663673,2.40502817],[-2.39529563,1.10011018],[-2.1959445,1.71060711],[-2.97219654,2.11575234],[-2.84580477,0.20557117],[-2.6173328,0.74921416],[-1.52159101,2.65001544],[-2.4433551,1.02685595],[-2.12929786,0.72600607],[0.19492455,-1.67703055],[-0.76991854,-3.11650723],[1.82199478,-2.65757475],[1.77235937,-4.37291202],[1.62185379,-2.73819575],[0.53052864,-2.87300213],[2.211509,-1.5945835],[0.75629947,-2.34063626],[0.48747361,-4.712812],[0.98946836,-1.6469933],[0.14140644,-2.45932312],[1.59394818,-3.54982431],[0.82900382,-1.49088422],[1.91330565,-3.10304953],[1.55071551,-1.3019889],[2.07262932,-2.83695848],[0.6309725,-2.43503632],[0.40672592,-3.17878599],[0.63487873,-1.64755885],[0.14652861,-2.56779286],[2.89050861,-4.12863705],[0.65470396,-3.0693579],[-0.89294102,-2.13657012],[1.93693144,-3.23388432],[1.79613072,-3.77096511],[1.81757032,-4.82310411],[2.04578013,-3.37053541],[1.16715492,-2.41535253],[-0.45211248,-2.70447155],[1.12654038,-2.70539792],[1.77919211,-3.27680203],[0.71004689,-3.606527],[2.45568189,-3.32399397],[2.70726689,-5.08994183],[1.46983163,-4.02313571],[1.20150021,-5.0482586],[1.43997273,-3.06096932],[0.52519365,-2.15182127],[1.7338365,-4.58949412],[2.20227891,-2.41147888]])
# Example 2
X = np.array([[62606,7.96],[48265,9.15],[42330,8.52],[47603,8.68],[42878,8.12],[40247,7.99],[10098,3.32],[2104,7.23],[8943,6.86],[11290,5.62],[55060,9.09],[6374,7.02],[33440,8],[9898,6.45],[34260,7.99],[30645,8.3],[56530,8.89],[83832,9.03],[54708,9.25],[75504,9.87],[58118,9.22],[49678,9.25],[51557,8.29],[50195,8.99],[65233,6.02],[42823,7.89],[81347,9.24],[42084,9.26],[22670,8.11],[23203,8.75],[16593,7.88],[17876,7.88],[22850,8],[9126,4.56],[7594,5.98],[11387,6.88],[4048,6.39],[3109,6.94],[2715,3.08],[9421,7.02],[6178,6.78],[15560,8],[6051,7.15],[2028,4.2],[3035,3.9],[23219,2.89],[70474,2.75],[1541,4],[1887,4.61],[5314,2.14],[4867,3.21],[507,1.55]])
# Example 3
Z = np.array([[1.38416797780957,0.484344328440116],[0.799874365341908,1.02175202153451],[0.558065384796926,0.73724206636689],[0.772902580148853,0.809498562917397],[0.580392481905376,0.556600824990623],[0.473197970058055,0.497892421543337],[-0.755159056808105,-1.61109407152458],[-1.08085762302151,0.154674062928429],[-0.802217080823178,-0.0124190853446179],[-0.706593546309433,-0.572406933611046],[1.0767222209111,0.994655835328071],[-0.90688553423852,0.0598374112058886],[0.195861199953642,0.502408452577743],[-0.763307632395131,-0.197576357755292],[0.229270359860446,0.497892421543337],[0.0819848561249604,0.637889383609944],[1.13661425147574,0.904335214639938],[2.24897630486059,0.967559649121631],[1.06238072787793,1.06691233187858],[1.90966961741685,1.34690625601179],[1.20131394163672,1.05336423877536],[0.857444051864243,1.06691233187858],[0.933999919504348,0.633373352575536],[0.878508119756704,0.949495524984004],[1.49119951814515,-0.391765692234779],[0.578151623618944,0.45273211119927],[2.1477302531918,1.06239630084417],[0.548042636824884,1.07142836291298],[-0.242939595407682,0.552084793956216],[-0.221223641468259,0.841110780158244],[-0.490534064619452,0.448216080164863],[-0.438260952228683,0.448216080164863],[-0.235605877379359,0.502408452577743],[-0.794761134161049,-1.05110622325815],[-0.857179223157665,-0.409829816372405],[-0.702641487149726,-0.00338702327580474],[-1.00165346831563,-0.224672543961732],[-1.03991103069671,0.0237091629306356],[-1.05596372460315,-1.71947881635034],[-0.782741985170187,0.0598374112058886],[-0.914871138313805,-0.0485473336198714],[-0.532621457526439,0.502408452577743],[-0.920045483811567,0.118545814653176],[-1.08395408174458,-1.21368334049679],[-1.04292600366391,-1.34916427152899],[-0.220571755421297,-1.80528340600407],[1.70473294140316,-1.86850784048576],[-1.10379586329899,-1.30400396118493],[-1.08969882753344,-1.02852606808612],[-0.950072984849755,-2.14398573358457],[-0.968285051286758,-1.66077041290306],[-1.14592399908391,-2.41043156461456]])Since each of these data sets contains 2-dimensional data, you can plot the clusters when you are done with this code.
import matplotlib.pyplot as plt
for cluster in clusters:
clusterArray = np.array(cluster)
plt.plot(clusterArray[:,0], clusterArray[:,1],'o')
plt.show()Today we talked about some disadvantages of k-means clustering. We looked at the last two examples from Wednesday’s workshop and we observed that they look the same when you graph them. The only difference is the scale. The x-values in the first example are much more spread out than than the x-values in the second. Because of that, your clusters end up very different. When the x-values are much larger than the y-values, differences in the y-values get drowned out by the differences in the x-values, so you end up basing your clusters only on the x-values (see the left image below).
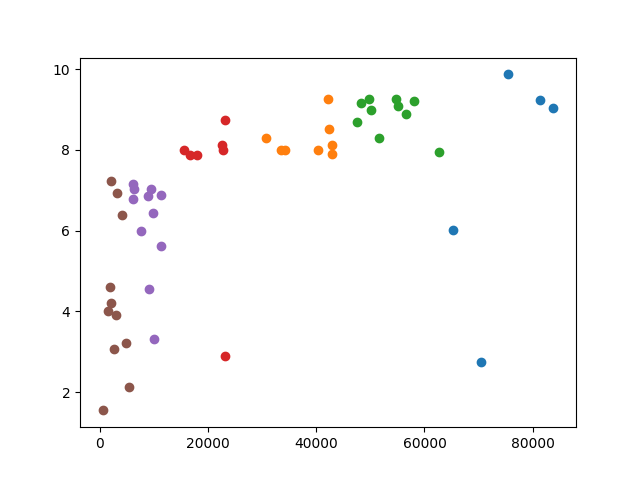
|
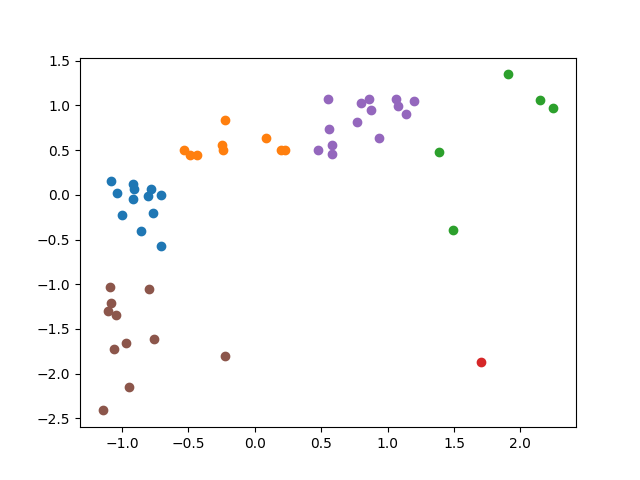
|
Standardizing the x-values and the y-values so they have similar spreads fixes the problem (right image above).
We talked about how to standardize data by computing z-values.
where is the average of the data and is the standard deviation. I briefly described how to find the standard deviation in Excel and numpy.
Another problem that arises in k-means clustering is the curse of dimensionality. The curse of dimensionality refers to several problems that arise when dealing with high dimensional data including:
We looked at this Google Colab example.
One way to deal with the curse of dimensionality is to use dimension reduction techniques, which we will talk about next week.
We finished by briefly mentioning some applications of k-means clustering including
| Day | Topic |
|---|---|
| Mon, Mar 25 | Principal component analysis |
| Wed, Mar 27 | k-Nearest neighbors algorithm |
| Fri, Mar 29 | Dimension reduction |
Today we talked about dimension reduction using principal component analysis. Principal component analysis is an idea from linear algebra that allows us to take data vectors where the dimension is very large and replaced them with vectors in a much lower dimensional space that still capture most of the information that was contained in the original vectors. Principal component analysis is one of the most commonly used methods for dimension reduction.
Let be an -by- data matrix with rows that are each -dimensional. Let be the row vector with entries equal to the average of each column of . Then the covariance matrix for is You can use the command np.cov(X.T) to compute the covariance matrix for . (Note: you need to compute the transpose of because numpy defines the covariance matrix in terms of -by- data matrices, which is the opposite of how we defined them).
By the spectral theorem from linear algebra, there is a diagonal matrix (with decreasing diagonal entries) and a matrix with orthogonal columns (both -by-) such that The columns of are the principle components of . You can transform the data matrix into a new data matrix with uncorrelated variables (orthogonal columns) by calculating . You can also create a reduced data matrix by computing where is the submatrix of containing only the first columns (the first principal components). You can also reduce the dimension of a single row vector by computing which will be in .
Here is numpy code to find the matrices and . Note that numpy puts the diagonal entries (which are called the eigenvalues of ) in increasing rather than decreasing order. Therefore we need to choose the last k columns of if we want .
import numpy as np
Q = np.cov(X.T)
d, W = np.linalg.eigh(Q)
k = 2 # choose how many dimensions you want
Wk = W[:,-k:] # use the last k columns of W
Tk = X @ WkIn order to recover (approximately) the original data matrix, you can compute
If , then this will completely recover the data matrix , otherwise you’ll get a matrix that is the same shape as , but the data in it will be compressed.
We finished class by doing a principal component analysis of 28 images of faces from the Yale face database B.

Today we talked some more about principal component analysis. We started with a simple data matrix with 2 dimensional rows.
X = np.array([[-1.176,-0.381],[4.299,5.560],[-1.270,-0.504],[1.110,0.872],[0.993,-2.293],[1.072,-2.637],[-0.706,0.130],[-0.769,0.933],[1.994,1.891],[-0.519,-0.583],[-2.484,-3.332],[0.242,0.079],[2.637,6.201],[-2.355,-3.816],[2.235,5.870],[0.835,2.000],[0.102,-1.634],[-0.404,-1.923],[0.751,4.235],[-1.180,-2.588],[-0.527,2.032],[2.563,2.954],[-1.812,0.269],[-1.063,-2.531],[-0.452,3.400],[1.005,0.904],[1.989,1.574],[-1.513,-1.100],[-1.587,-0.461],[0.019,-0.514],[1.394,2.163],[-1.424,0.307],[0.665,-0.568],[1.026,3.185],[-1.818,-0.114],[-3.490,-3.137],[-2.007,-0.326],[-0.130,0.283],[-0.010,-0.191],[-1.199,-1.026],[-1.886,-3.086],[-0.607,-0.866],[-1.525,-2.866],[-1.128,-1.697],[0.240,-2.340],[-2.117,-2.566],[-2.671,-3.556],[3.018,3.430],[-0.965,-1.628],[0.943,-0.191],[0.451,1.524],[2.159,1.307],[-1.651,-2.146],[0.476,-1.478],[1.849,3.421],[2.680,2.693],[2.079,3.357],[0.545,2.885],[-0.111,-2.637],[-0.938,-1.413],[-2.806,-5.201],[-1.805,-5.043],[-2.149,-1.782],[0.486,1.523],[2.796,3.460],[0.814,0.354],[-1.004,-3.153],[2.803,3.223],[1.253,1.898],[0.512,0.986],[-1.541,1.040],[-1.611,0.366],[-0.376,-0.378],[2.057,0.716],[-1.308,-2.566],[0.774,2.805],[-0.154,0.801],[0.932,0.937],[0.447,2.937],[1.623,3.251],[-0.522,-0.423],[-0.022,0.747],[-0.419,-2.039],[0.978,1.541],[1.116,1.625],[-0.135,2.210],[-0.111,-2.899],[-1.254,-0.457],[0.078,-0.065],[-0.214,-1.166],[-2.644,-2.199],[1.780,3.323],[1.521,2.152],[-0.276,-0.841],[-2.044,-3.149],[1.273,3.503],[-0.702,-1.164],[0.575,1.964],[0.465,1.100],[1.454,1.448]])We computed the covariance matrix for and found its eigenvectors. You can see the data and the two eigenvectors here:
The red eigenvector points in the direction of maximum variability. The other eigenvector is perpendicular to the red one. The eigenvectors in principal component analysis are always mutually orthogonal (perpendicular to each other).
Here is another example in 3-dimensions:
np.array([[0.539,-2.63,0.306],[0.248,-4.35,-0.841],[-1.89,3.34,-1.08],[1.28,-3.35,2.06],[0.52,-2.26,0.0225],[-1.59,-1.36,-1.37],[-0.476,1.98,0.624],[0.36,-1.04,-0.451],[-0.803,-1.79,-1.14],[0.152,-0.489,1.27],[-0.781,2.79,0.648],[-0.436,-0.203,-0.211],[-0.988,-0.888,-1.64],[0.363,-1.42,0.238],[-1.02,6.26,0.07],[1.47,-1.02,0.501],[0.608,-5.83,0.195],[1.07,1.51,1.54],[0.684,-0.659,0.831],[-1.31,0.964,-1.09],[0.127,0.855,-0.568],[1.94,-3.46,0.942],[0.319,-6.04,0.489],[-0.624,-1.19,-1.68],[0.317,0.415,2.18],[0.901,-2.64,0.241],[-0.816,-0.55,-1.13],[-0.372,1.24,0.143],[-0.409,6.93,1.3],[1.64,-7.51,0.545],[-0.833,3.05,0.776],[-0.451,0.0903,-0.00596],[-0.29,-0.529,-2.08],[-1.19,-0.957,-0.451],[-0.573,0.468,-0.416],[-1.32,1.0,-1.17],[0.213,-1.3,0.184],[1.9,-0.14,1.73],[-0.917,2.94,0.343],[1.44,-4.42,1.08],[0.315,2.86,0.894],[-0.0783,-0.0105,-0.857],[1.01,-1.97,1.24],[0.213,-0.708,0.198],[-1.84,2.11,-1.52],[-0.334,0.247,-0.595],[0.251,0.332,0.219],[-0.00107,0.589,-0.0736],[-0.825,-3.06,-1.29],[-1.46,2.57,0.355],[0.513,-1.9,-1.27],[0.977,-1.1,-0.0922],[-0.303,-3.36,-1.0],[0.233,2.39,1.45],[-2.11,-0.0848,-1.83],[-0.524,2.54,0.0703],[-0.457,-1.7,0.445],[0.295,-0.419,0.544],[-2.22,2.88,-2.25],[0.288,-0.0653,0.415],[-0.766,4.33,0.612],[-0.92,1.23,-0.399],[-0.0367,2.67,1.83],[-1.12,-1.58,-2.9],[0.78,0.755,0.408],[-1.68,7.15,-1.11],[-1.85,4.37,-0.954],[0.659,-1.21,-0.563],[0.378,-3.37,-0.126],[0.507,-0.321,-0.00401],[-0.226,-0.644,-0.629],[-0.712,2.01,-1.34],[-1.15,-2.24,-1.62],[0.778,1.95,0.365],[-0.227,-0.0463,-0.116],[0.155,0.0193,0.222],[0.317,0.685,-0.648],[-1.14,0.106,-1.49],[-0.582,-0.625,-1.36],[-1.3,1.36,0.0372],[-1.03,-0.818,-0.353],[-0.375,1.96,0.0616],[-0.408,3.1,0.983],[0.655,0.214,1.26],[-0.2,-0.418,-1.22],[0.137,0.836,0.523],[-2.18,8.95,0.156],[-0.449,-2.32,-2.0],[-0.398,-1.78,-0.755],[0.886,-0.523,2.47],[0.56,-4.45,0.234],[1.26,0.946,2.63],[0.807,-1.8,-0.74],[-0.341,3.25,-0.207],[1.96,-3.78,0.472],[-0.386,-0.14,-0.602],[-0.767,4.67,-1.14],[0.685,0.0478,1.29],[-1.14,-0.0269,-2.7],[0.494,-1.73,-0.111]])You should understand the following key ideas about principal component analysis.
The dominant principal component (the one with the largest eigenvalue) points in the direction of greatest variability in the data.
The principal components are all perpendicular (orthogonal) to each other.
You can use the principal components as an alternative coordinate system where it is easier to see which coordinates are the most important.
We finished today by introducing the k-nearest neighbors algorithm. This is a supervised learning algorithm used to predict how to label a new data point based on the labels for a collection of training data.
k-Nearest Neighbors Algorithm. Given and an set of labeled vectors , apply the following steps to predict how to classify a new point
Find the nearest elements of to .
If the majority of those elements have the same label, the that is the predicted label for .
There are lots of variants of this algorithm to decide what to do if there is not a clear majority. One option is to do a weighted k-nearest neighbors algorithm where the vote to decided the majority of the neighbors is weighted so that the votes of points that a closer to count for more.
The main disadvantage of the k-nearest neighbors algorithm is that it does not work well in higher dimensions because of the curse of dimensionality.
Today we did a workshop combining dimension reduction (with principal component analysis) and the k-nearest neighbors algorithm.
To get started, we used this code to load the data and do the principal component analysis.
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# Load the data
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Find the principal components
X = np.array([image.flatten() for image in x_train])
Q = np.cov(X.T)
d, W = np.linalg.eigh(Q)| Day | Topic |
|---|---|
| Mon, Apr 1 | no class |
| Wed, Apr 3 | Introduction to Markov decision processes |
| Fri, Apr 5 | Markov chains with rewards |
Today we introduced Markov decision processes (MDPs). MDPs are the theoretical foundation of a third type of machine learning called reinforcement learning which is different from the other two types we’ve studied before (supervised and unsupervised learning).
A Markov descision process has four parts:
We looked at the following very simple example of an MDP where there are three states (which you can think of as safe, risky, and dead). The safe state has a reward of 1 point per round, while the risky state earns 2 points per round. The dead state is absorbing, once you get there, you don’t get any more actions and your reward is zero from that point on. In the other two states, you can choose either the red or the blue action. The blue action corresponds to trying to play it safe, while the red action corresponds to preferring the risky state. The transition probabilities corresponding to the red and blue actions are shown in the graph below.
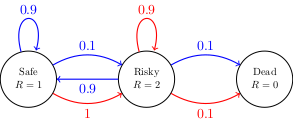
We started with this question:
If you always pick the same action, then the MDP is just a Markov chain with rewards. And always picking the red action results in a very simple Markov chain, so we were able to calculate the theoretical average reward. Depending on how long we are able to stay in the risky state before falling into the dead state, we have the following table of possible outcomes with their corresponding probabilities.
| Outcome (Total Reward) | |||||
| Probability |
When an outcome like the total reward is determined randomly by a probability distribution, the expected value (also known as the theoretical average) is the weighted average of the possible outcomes with the probabilities as the weights. The possible outcomes are where is the number of times you return to the risky state (before falling in the hole and ending up dead). The probabilities of those outcomes are . So the expected reward is an infinite sum which we denoted with the letter :
You could use a computer and add up the first few thousand terms of this series to approximate the sum, but we used algebra to work out the following recursive formula for the sum: This recursive formula makes intuitive sense if you think about it, since the expected reward after the current round is the 2 points we earn for the current round plus a 10% chance of getting nothing (if we die) or a 90% chance of starting over again at the risky state with an average future reward of .
Next time we will tackle the more complicated question of what happens if you always pick the blue action. It turns out we will be able to find a similar recursive formula to get the answer.
Today we continued the example we started on Wednesday. This time we asked what is your theoretical average total reward if you start in any state and always choose the blue action. Notice that if you always choose the blue action, then the transition matrix is
These three numbers are the entries the expected value vector, which we’ll just denote by . We can set up a recursive formula for the value vector much like we did for the expected value last time. It is a little more complicated, since it is a system of equations:
This makes sense because the expected value for state 1 (the safe state) is 1 (for the reward you earn this round) plus a 90% chance that you will end back in state 1 and get again plus a 10% chance that you will start the next round in state 2 (the risky state) where you have an expected value of .
We can re-write this system of equations using the transition matrix and a reward vector . Then the recursive formula is:
You can solve this equation for using linear algebra (row reduction), but there is a better way. The key idea is that is a function of which we can call . We are looking for a fixed point of . We can use a technique called fixed point iteration or value iteration.
Value Iteration Algorithm. Input a transition matrix , a reward vector , and an accuracy level .
The following theorem tells us when this algorithm will converge for a Markov chain with rewards.
Theorem. If we have a Markov chain with transition matrix and reward vector such that in every state that is in a final class of the Markov chain, then the value iteration algorithm will converge to the value vector .
We implemented the value iteration algorithm in Python and used it to find the value vector for the blue action in the MDP from last time. Then we also did the following example.
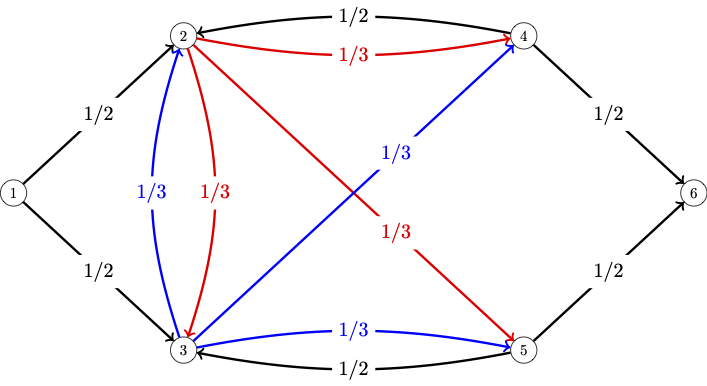
| Day | Topic |
|---|---|
| Mon, Apr 8 | Markov chains with rewards - con’d |
| Wed, Apr 10 | Review |
| Fri, Apr 12 | Midterm 2 |
Today we did this workshop in class:
Be sure to also look at the study guide for the midterm on Friday.
Today we did an in class review for Friday’s midterm. We looked at some of the questions from the study guide. We also talked about neural networks and did the following examples.
Draw a computation graph for the function .
Use the backpropagation algorithm to find the gradient of at .
Suppose a neural network inputs 40-by-40 pixel grayscale images, has two hidden layers with 100 nodes each, and has an output layer with 10 nodes. How many real number parameters does this neural network have?
Why does each layer of a neural network combine an affine linear map with a nonlinear activation function?
| Day | Topic |
|---|---|
| Mon, Apr 15 | Markov decision processes |
| Wed, Apr 17 | Optimal policies |
| Fri, Apr 19 | Policy iteration algorithm |
Today we looked at this example of a Markov decision process.
The states are the squares in the grid (except the gray square which cannot be entered). Each square has a reward of zero, except the green square which has a +1 reward and the red square which has a -1 reward. The green and red squares are also absorbing… once you reach them, the game ends (and you are stuck there forever).
The agent can move up, down, left, or right from any square, but must stay on the grid. If they try to move into an invalid square, then the stay at their current position. Furthermore, the agent isn’t in complete control of how they move. When they try to move in one direction, there is a 80% chance they will move one step in that direction, but also a 20% chance of moving perpendicular to the desired direction (equally likely to go left or right).
Let’s label the states with the numbers 0 through 10:
| 0 | 1 | 2 | 3 |
| 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 |
Before calculating the value for each state, we need to deal with one problem. Since the only states where we get any nonzero reward are absorbing states that you get stuck in forever, the value in the green state would be and the value in the red state would be . The way we deal with nonzero rewards when they are in states that are in final classes of a Markov chain or Markov decision process is to use discounting. The idea is to discount the value of future rewards in the value iteration equation by multiplying them by a discount factor . The smaller is, the more we will focus on immediate rewards, and the less we will care about the future. For Markov chains with rewards, the value iteration formula with discounting is
For Markov decision processes, where the agent can choose different actions at each state, the value iteration formula is a little more complicated. In general, if the set of actions available to the agent is , and for every , there is a transition matrix corresponding to that action, then the value iteration formula (which is known as the Bellman equation in this context) is where the maximum is taken entrywise over the different vectors , , etc.. Note that this is not the standard way to write the Bellman equations, but it is equivalent to those other notations, and it is particularly convenient if you can construct the full transition matrix for each action (which isn’t always easy or efficient!).
We wrote a Python program to find the value for each state of the MDP above with a discount factor of . We got these results.
Today we talked about finding optimal policies for an MDP. A policy for a Markov decision process is a function that inputs states and outputs actions: where is the set of states and is the set of actions.
Before we described how to find the optimal policy, we took a look at the Bellman equation again.
The entries of the value vector are given by the following recursive formula
where is the state, is the value vector, is the discount factor, is the set of possible actions, and is row of the transition matrix if you choose action .
Once you know all of the entries of the value vector , you can use them to choose the best action in each state. We looked at the example from Monday and figured out the best action in state 9 based on the values of the neighboring states. From that example, we derived the following formula for the optimal policy.
Given the value vector , the optimal action at each state is given by the function
We programmed this function in Python for the example from last time. We also observed how the value vector and the optimal policy can chance if you increase or decrease the discount factor. For example, when you increase the discount factor, it makes the agent more concerned with future rewards and less concerned about the present. So the agent tends to pick actions that are more cautious.
Today we started by talking about an alternative to the value iteration algorithm called policy iteration. With policy iteration, you can (in theory) get both the exact value vector and the optimal policy for a Markov decision process in a finite number of steps. Here is the algorithm:
Since there are at most possible policies, this algorithm is guarantee to find the correct solution after a finite number of steps. Unfortunately, step 3 is usually solved using value iteration, so the policy iteration algorithm usually isn’t any faster than value iteration.
After we talked about policy iteration, we talked about some of the practical issues with implementing MDPs in Python. One recommendation is to implement an MDP using a Python class:
class MDP:
def __init__(self, states, actions, rewards, transitionFunction, discount):
self.states = states
self.actions = actions
self.rewards = rewards
self.transitionFunction = transitionFunction
self.discount = discount We didn’t go into details, but we did talk about one issue with large MDPs. If there are a lot of states, then the transition probability function which is the probability of moving from state to state if you take action is zero for most combinations of the input. Therefore, when you calculate the Bellman equation, most of the entries of the vector are zeros. This is an example of a sparse vector (i.e., it has a lot of zero entries). It would save computer time if we didn’t keep track of all of those zeros.
Therefore, when we create a MDP object, we might want to express our transition function differently. We could create a function which computes for any state and action a list that contains tuples (j, p) where is a possible future state and is the probability to reach that state. For example in the grid world we could use code like this:
# Example
T(9,"up") # should output [(5, 0.8), (8, 0.1), (10, 0.1)]
# Bellman equation
new_v[i] = R[i] + discount * max(np.dot([t[1] for t in T(i,a)], [v[t[0]] for t in T(i,a)]) for a in actions)| Day | Topic |
|---|---|
| Mon, Apr 22 | Markov decision process examples |
| Wed, Apr 24 | Q-learning algorithm |
| Fri, Apr 26 | Q-learning continued |
| Mon, Apr 29 | Review |
Today we did the following workshop.
I recommend using the following MDP class to solve each of the problems. Notice that the last problem requires you to add discount factors to the MDP class, since I did not include that in the original code.
import numpy as np
class MDP:
def __init__(self,states,actions,rewardFunction,transitionFunction):
self.states = states
self.actions = actions
self.reward = rewardFunction
self.transitionFunction = transitionFunction
self.value = self.findValue()
self.optimalPolicy = self.findOptimalPolicy()
def transition(self, s, a):
return self.transitionFunction(self.states, s,a)
def qvalue(self, s, a, v):
outcomes = self.transition(s, a)
probabilities = [pair[1] for pair in outcomes]
nextStates = [pair[0] for pair in outcomes]
nextValues = [v[s] for s in nextStates]
return np.dot(probabilities,nextValues)
def bellman(self, v):
return {s:self.reward(s) + max(self.qvalue(s, a, v) for a in self.actions) for s in self.states}
def findValue(self):
# Uses the value iteration algorithm
v = {s: 0 for s in self.states}
new_v = self.bellman(v)
while sum((new_v[s]-v[s])**2 for s in self.states) > 10**(-6):
v = new_v
new_v = self.bellman(v)
return new_v
def findOptimalPolicy(self):
return {s:np.argmax([self.qvalue(s, a, self.value) for a in self.actions]) for s in self.states}When you are doing the workshop, make sure to pay close attention to the types of the inputs and outputs for each function:
states is a Python list of states (in most examples, each individual state will by a Python tuple).actions is a Python list of actions (the individual actions could be strings like “up” or numbers or anything).rewardFunction is a function that inputs states and outputs the number for the reward.transitionFunction needs three arguments:
states),s, anda.[(s1, p1), (s2, p2), ...] where the first entry of each tuple is a possible next state and the second entry is the probability of getting to that state.Another thing to notice in the class is the qvalue method. A q-value is the expected future value if we are in state and select action . Previously we didn’t use a name for this quantity, but it is where is the value vector, and is the probability vector for the possible transitions if we are in state and choose action . It is convenient in the class to make this a separate function.
Today we introduced Q-learning which is one of the main algorithms used for reinforcement learning. The idea is similar to a Markov decision process, but there are two important differences:
Instead, our AI will have to learn the environment as it goes. At first it will choose actions at random and just see what happens. As it goes, it will store information about the expected values of state-action pairs in a table called a Q-table
| action0 | action1 | action2 | ||
| state0 | ||||
| state1 | ||||
| state2 | ||||
Initially, we set all of the entries of the Q-table to zero. Then, any time our agent starts in state , chooses action , and ends up in state , we will update entry in the Q-table using the q-learning update formula:
where is a learning rate between 0 and 1, and is the discount factor (same as for an MDP). Note, if is one of the final absorbing states, then there is no state that comes next, so you can leave off the term in the formula.
The Q-learning algorithm combines this formula for updating the Q-table with a second rule about how our agent moves around the environment. We could just let our agent choose actions at random. Or we could ask it to try to find the best policy given its current Q-table. Instead we do a mix of both options. This is called an epsilon-greedy algorithm where we choose a constant between 0 and 1, then in each state,
By mixing random actions with optimal actions, the AI can still perform reasonably well even as it learns the environment. When our agent reaches an end state, instead of staying there forever, we will reset the agent back to the start state. This is called an episode. Typically in Q-learning we simulate many episodes, to let the AI develop an accurate Q-table.
Notice that the agent never really learns what the transition function or the rewards are. It just learns the values in the Q-table. So it never really has a complete model of the game (Q-learning is called a model-free algorithm for this reason). But that is okay because our AI can figure out what to do from the Q-table, and the Q-table will converge to the correct table of values in the long run.
We finished by playing with the following code in class to see how a simple Q-learning example works.
Today we talked some more about the Q-learning algorithm:
Q-learning algorithm.
Some important differences between -learning and MPDs to keep in mind:
The parameters and are hyperparamters. They don’t change what the underlying MDP is, but they do affect the rate at which the AI learns. It can be hard to predict in advance what values of the hyperparameters to choose. Sometimes a little trial and error is a good idea.
After reviewing the Q-learning algorithm, we updated the grid world example with randomness and we saw how to program the Q-learning algorithm and how it differs from solving an MDP.
We also talked about how to implement an AI that can play blackjack with Q-learning. We discuss good choices for the states, actions, rewards, and transition function.
Today I handed out the final class project. It is due on Thursday at noon. To complete the project, you need to use reinforcement learning to train an AI to play tic-tac-toe (like in this scene from the movie WarGames).
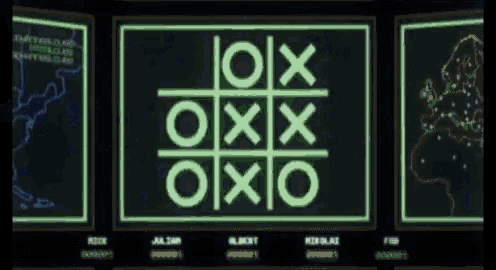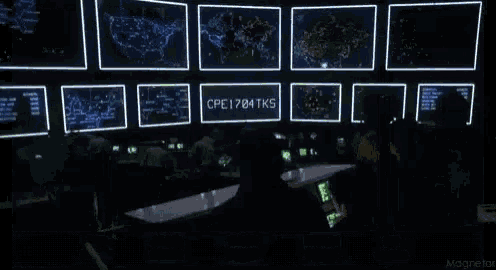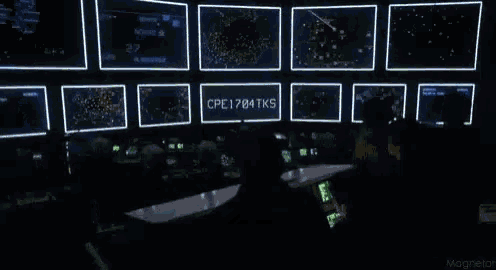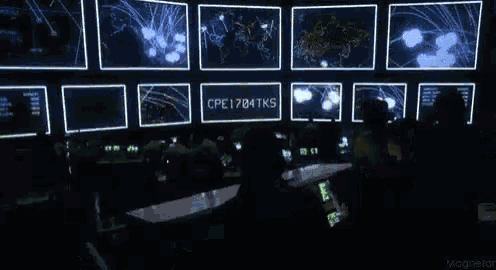
For the final project, you are welcome to copy and/or modify the following helper functions:
def gameOver(s):
# returns True if the game is over, otherwise False
if '.' not in s:
return True
else:
rows = [[0,1,2],[3,4,5],[6,7,8],[0,3,6],[1,4,7],[2,5,8],[0,4,8],[6,4,2]]
rowValues = ["".join(s[k] for k in row) for row in rows]
if "XXX" in rowValues or "OOO" in rowValues:
return True
else:
return False
def generateAllStates():
# returns a list with all possible state strings for tic-tac-toe
states = [""]
for i in range(9):
states = [s + c for c in ['X','O','.'] for s in states]
return states
def replaceCharacter(s, position, replacement):
# returns a new string where the character in s at position is replaced with replacement
return s[:position]+replacement+s[(position+1):]